TL;DR · 本文论证:Langfuse 是当前最完整的开源 + self-hostable + framework-agnostic 的 LLM 可观测栈;它的真正护城河不是 trace UI,是把"调用观测 + Prompt 治理 + Eval + 离线回归"四件事缝合在一个数据模型上的设计。 · 写给:要做 LLM 可观测选型的工程师 / 架构师 / SRE——特别是国内合规敏感、数据必须留在自己基础设施内的团队。 · 不读会错过:Langfuse 与 LangSmith 的本质差异、self-hosted v3 架构(5 个组件起步)的真实运维成本、Prompt 版本化闭环的工作机制。
截至时间:2026-06。 本文所有关于 Langfuse 功能 / 架构 / 许可的描述基于这个时间点的公开版本(Langfuse v3.x),Langfuse 迭代极快,读者使用本文做决策前请核对最新 docs。
L4-0 把 Langfuse 放在"Trace-first 专用平台 · 开源代表"的位置。L4-1 把它拆开看:它解决的是什么问题?数据模型怎么设计的?self-hosted 架构如何演化的?强项 / 弱项分别在哪里?什么场景该选它、什么场景不该选?
Langfuse 对国内团队的特殊意义在于:它是目前最完整的开源、self-hostable、框架中立的 LLM 可观测栈——所有"数据不能出境"的合规场景里,它几乎是默认起点。
1. 它解决了什么核心问题
LLM 应用团队在生产化过程中通常会撞上四类问题,几乎同时出现:
- 看不见调用细节——一次 LLM 调用到底用了什么 prompt、什么 model、消耗了多少 token、返回了什么——没有就 debug 不下去。
- prompt 是不版本化的代码——改一个字 prompt 行为可能崩塌,但 prompt 通常硬编码在源码里、和发布流程绑死、回滚困难。
- 质量没有客观度量——“上次改完更好了吗?"——除了开发者主观感受,没有可量化的答案。
- 离线测试集没人维护——黄金集是哪些?谁加的?这次发布是否回归?通常都散落在 spreadsheet 里。
市面上有针对每个问题的独立工具,但把这四件事用一个数据模型贯穿起来的开源产品,截至 2026-06 基本只有 Langfuse 一家。这是它的核心立足点。
flowchart LR
P1["调用可观测
(Trace + Observation)"] --- M((统一数据模型))
P2["Prompt 版本治理
(PromptTemplate)"] --- M
P3["质量评估
(Score + Eval)"] --- M
P4["离线回归集
(Dataset + DatasetRun)"] --- M
M -.->|"同一系统、同一查询面"| OUT["开发 → 部署 → 观测 → 回归 → 改进 闭环"]
style M fill:#e0eaff
图 1·Langfuse 把"可观测 + prompt 治理 + 评估 + 回归"四件事缝在一个数据模型上。其他工具通常只覆盖其中一两件。
2. 数据模型
Langfuse 的数据模型是这一切的地基。把它讲清楚比讲它的功能清单重要得多——因为所有功能都是这个模型的查询投影。
核心七层
| 概念 | 角色 | 类比 |
|---|---|---|
| Trace | 一次任务 / 请求的顶层容器 | OTel Trace |
| Observation | Trace 内的最小执行单元,分三种 | OTel Span 的细化 |
| └ Span | 通用时间区间操作(chain step、工具调用、retrieval) | OTel Span |
| └ Generation | 特化的 LLM 调用 span(含 model、prompt、token usage) | 没有传统对应 |
| └ Event | 瞬时点事件(如"重试触发”、“cache miss”) | OTel Span Event |
| Score | 挂在 trace 或单个 observation 上的评估分数 | 没有传统对应 |
| Session | 把多个 trace 串成同一会话(多轮对话) | Web session |
| User | 把 trace 绑定到用户标识 | 业务实体 |
| PromptTemplate | 独立的、可版本化的 prompt 对象 | Git 仓库里的代码文件 |
| Dataset / DatasetItem / DatasetRun | 离线评估的输入集 + 一次完整 run | ML 测试集 |
flowchart TD
User[("User
用户标识")] -.->|"持有"| Session
Session[("Session
多轮对话容器")] --> Trace1["Trace 1"]
Session --> Trace2["Trace 2"]
Trace1 --> O1["Observation: Span
通用操作"]
O1 --> O2["Observation: Generation
LLM 调用"]
O1 --> O3["Observation: Event
瞬时事件"]
O2 --> O4["Observation: Span
(嵌套)"]
Score1["Score · trace-level
整体评分"] -.->|"attach"| Trace1
Score2["Score · obs-level
单步评分"] -.->|"attach"| O2
PT["PromptTemplate v3
label: production"] -.->|"引用"| O2
DS[("Dataset
黄金集")] -.->|"DatasetRun 执行"| Trace1
style O2 fill:#e0eaff
style PT fill:#fff4d6
style Score1 fill:#e8f5e9
style Score2 fill:#e8f5e9
图 2·Langfuse 数据模型核心。Generation 是被特殊化的 Span 子类——它显式承载 LLM 调用的语义;PromptTemplate 是独立可版本化对象,与 Generation 通过引用关联。
三个值得展开的设计
Generation 不是普通 Span。 它是被命名、被 schema 约束的"LLM 调用"。这件事的工程意义在于:让 model name、prompt、token usage、cost、temperature 这些字段成为一等公民,而不是埋在杂七杂八的 attribute 里。Langfuse 的 cost 看板、token 看板都建立在这个特化之上。OpenTelemetry GenAI Semantic Conventions 走的是类似路线,区别在于命名空间——OTel 用 gen_ai.*,Langfuse 用自己的字段名。这是 Langfuse 与 OTel 长期需要收敛的地方。
Score 可以挂在两层。 既可以挂 trace(整体评分:“这次对话满意吗”),也可以挂单个 observation(单步评分:“这次 retrieval 的相关性几分”)。这让一次 trace 在不同分析维度上能携带多套独立的质量信号。
PromptTemplate 与 Generation 解耦。 Prompt 不是 trace 数据的附庸,是独立的可版本化对象,有自己的生命周期(draft → label: staging → label: production),可以被多个 Generation 引用。这把"prompt 是代码"工程化了。
一个真实 Generation 对象长什么样
下面是 Langfuse API 返回的一个 Generation observation 的简化 JSON 形态(截至 2026-06 schema,字段名以官方文档为准):
{
"id": "obs_01HM4Q8X...",
"trace_id": "trace_01HM4Q...",
"type": "GENERATION",
"name": "gpt-4-response",
"start_time": "2026-06-01T10:23:45.123Z",
"end_time": "2026-06-01T10:23:47.456Z",
"model": "gpt-4",
"model_parameters": {
"temperature": 0.7,
"max_tokens": 200
},
"input": [{ "role": "user", "content": "我的账单为什么涨了?" }],
"output": { "role": "assistant", "content": "..." },
"usage": {
"input": 1024,
"output": 256,
"total": 1280,
"unit": "TOKENS"
},
"prompt_id": "prompt_01HM3...",
"prompt_name": "complaint-prompt",
"prompt_version": 3,
"level": "DEFAULT",
"parent_observation_id": "obs_01HM4Q7..."
}
注意三个细节:
prompt_*字段直接挂载——是不是用了哪个 PromptTemplate、哪个版本,每次调用都自带;不需要外部 join。usage是 LLM-specific 子结构——独立于 OTel attribute,区别于普通 Span。parent_observation_id形成嵌套树——一次 Agent 任务里的多层 Span / Generation 通过这个字段构成因果链。
SDK:两种典型用法
Python SDK(截至 2026-06 v3.x)提供两种使用模式:
# === 模式 1:装饰器(推荐用于自动追踪整条链路)===
from langfuse import Langfuse
from langfuse.decorators import observe
from langfuse.openai import openai # 注入 OpenAI SDK,自动产生 Generation
langfuse = Langfuse(
secret_key="sk-lf-...",
public_key="pk-lf-...",
host="https://your-langfuse.internal", # self-hosted URL
)
@observe() # 自动创建 Trace
def handle_complaint(user_query: str, user_id: str) -> str:
prompt = langfuse.get_prompt("complaint-prompt", label="production")
response = openai.chat.completions.create( # 自动产生 Generation
model="gpt-4",
messages=prompt.compile(query=user_query),
temperature=0.7,
)
return response.choices[0].message.content
# === 模式 2:手动 API(精细控制 Span / Generation)===
trace = langfuse.trace(
name="customer-support",
user_id="user-123",
session_id="session-abc",
metadata={"feature": "complaint-handler"},
)
gen = trace.generation(
name="gpt-4-response",
model="gpt-4",
model_parameters={"temperature": 0.7, "max_tokens": 200},
input=[{"role": "user", "content": "..."}],
prompt=langfuse.get_prompt("complaint-prompt", label="production"),
)
# 调用 LLM ...
gen.end(
output={"role": "assistant", "content": "..."},
usage_details={"input": 1024, "output": 256},
)
trace.score(name="helpfulness", value=0.8) # 上报评分
模式 1 是 90% 团队的入口——少几十行胶水代码就能跑起来。模式 2 留给"已经在自研框架里手控 chain step"的场景。这种两层 API 并存的设计是 Langfuse 易用性的关键,也是它区别于"只有一种用法"工具的地方。
3. Self-hosted 架构的演化
Langfuse 早期(v2)只用 PostgreSQL 存所有数据。这个方案简单,但跑到一定流量就崩——LLM trace 数据的写入特征(高吞吐、宽 schema、长 payload)和 Postgres 的事务型设计天然不合。
v3(2024 年的大重构)把架构拆成五层:
flowchart LR
SDK["Langfuse SDK
Python / TS
+ OTel 接收"] -->|"SDK / OTLP"| WEB["Web
Next.js"]
WEB --> PG[("Postgres
元数据:
prompts / users / scores /
datasets / config")]
WEB -->|"异步入队"| Q["Redis
队列 + 缓存"]
Q --> W["Worker
后台任务"]
W --> CH[("ClickHouse
列存:
traces / observations
高写入量、聚合查询")]
W --> S3[("S3-compatible
blob:
大 payload / 媒体")]
WEB --> CH
WEB --> S3
style CH fill:#fff4d6
style PG fill:#e0eaff
style S3 fill:#e8f5e9
图 3·Langfuse v3 self-hosted 架构。Postgres 装元数据,ClickHouse 装高写入量的 trace 数据,Redis 做队列与缓存,S3 兜底大 payload。这是从 v2 单 Postgres 架构升级而来的扩展方案。
为什么必然走向列存
v2 的 Postgres 撑不住的根因,就是 L1-3 讲过的状态空间体积:每条 LLM trace 携带几十个属性(model、prompt、tokens、user_id、tenant_id、prompt version、custom tags),单条 payload 可能上百 KB(prompt + context + response),事件量随业务线性增长。这是典型的"宽事件 + 高写入"工作负载——列存(ClickHouse、Apache Doris 这一类)是为此而生的。
Langfuse 截至 2026-06 选了 ClickHouse。同样的工作负载用 Apache Doris 也跑得起来——Doris 在高并发交互式查询(比如 Langfuse UI 上多个用户同时翻看不同租户的 trace)和复杂 Join(trace × score × dataset)场景下尤其强,且 MySQL 协议兼容降低了运维门槛。社区里有 self-hoster 在自行实验用 Doris 替换 ClickHouse,但官方目前只支持后者。
架构对运维的实际含义
部署复杂度:v3 之后 self-host 一份 Langfuse 至少要跑 5 个组件(Web + Worker + Postgres + Redis + ClickHouse),加 S3-compatible 存储就是 6 个。这比"docker compose up"的玩具部署重得多,对中小团队的运维能力提出了实际要求。
好消息:Langfuse 官方提供完整的 Helm chart 和 docker-compose,大部分坑都被踩平了。
坏消息:ClickHouse 本身的运维(compaction、retention、分区、副本)需要团队有列存背景,否则只能用单机版"将就跑"。
Langfuse Trace 详情页 UI 长这样
下面是 Langfuse v3.82.0 公开 demo 中一次真实 trace 的详情页截图。看懂这个布局后,前面 JSON schema 里的每个字段都能在 UI 里找到位置。
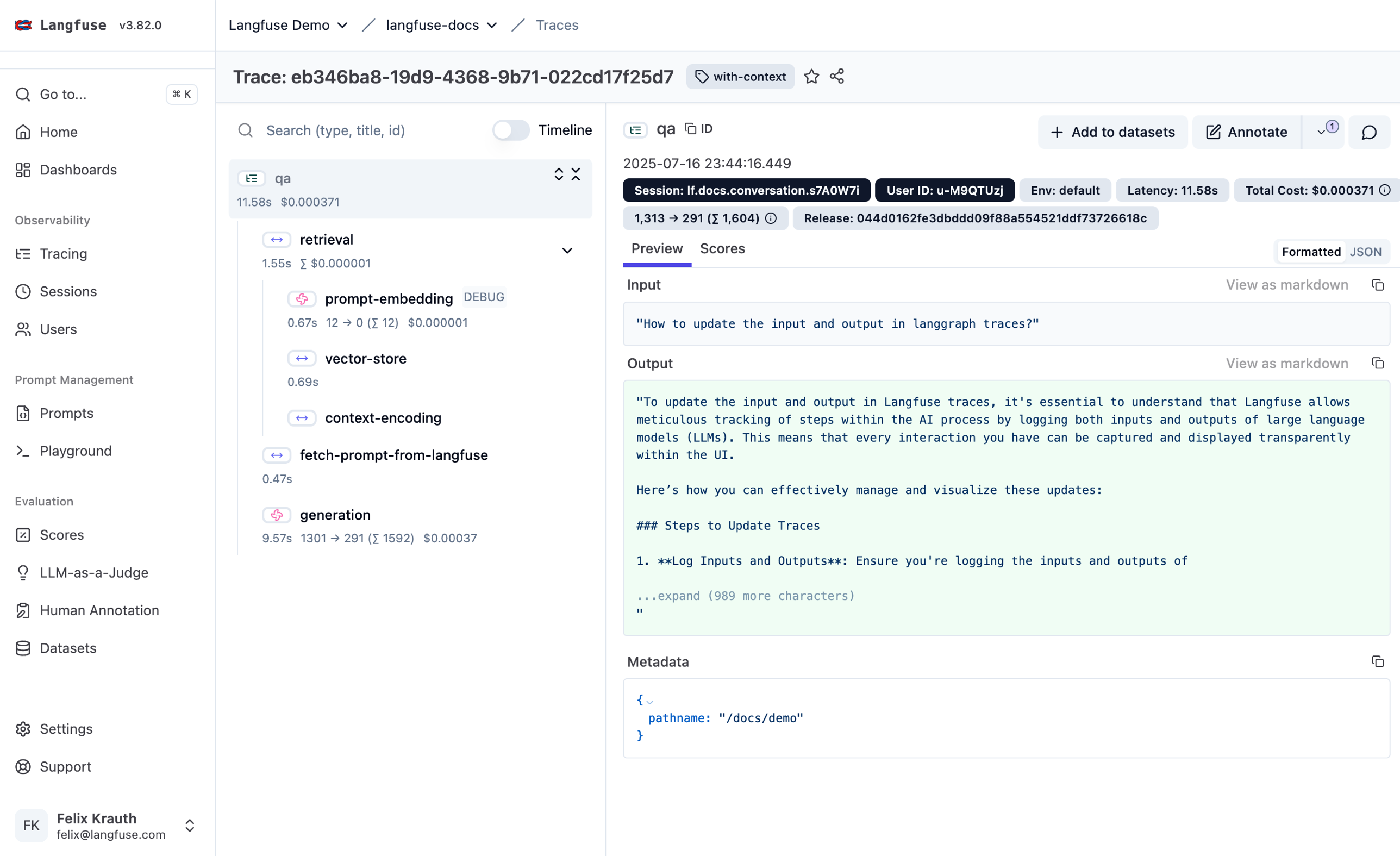
图 4·Langfuse Trace 详情页(v3.82.0,来自官方 demo)。左:导航栏(Tracing / Sessions / Users / Prompts / Playground / Scores / LLM-as-a-Judge / Human Annotation / Datasets——基本就是数据模型在 UI 上的投影)。中:span 树(qa 根节点下含 retrieval → prompt-embedding / vector-store / context-encoding、fetch-prompt-from-langfuse、generation,每条都标了延时和 token / 成本)。右:选中 observation 的 input / output / metadata + cost + token usage——前文那个 Generation JSON 的每个字段在这里都能直接对位上。
4. 核心功能模块
4.1 Prompt Management 闭环
这是 Langfuse 相比纯 trace 工具的关键差异。
flowchart LR
A["开发者
在 Langfuse UI
编辑 prompt v3"] --> B["发布
label: staging"]
B --> C["staging 流量调用
fetch('my-prompt', label='staging')"]
C --> D["Trace + Generation
带 prompt version = v3"]
D --> E["Eval
LLM-as-Judge / 黄金集对比"]
E -->|"v3 分数 ≥ v2"| F["切到 label: production
全量上线"]
E -->|"v3 分数 < v2"| G["回滚 label
或修改后再来"]
F --> A
G --> A
style E fill:#e0eaff
图 5·Langfuse 的 prompt 版本闭环。从 UI 改 prompt → 灰度部署 → trace 自动带 version → eval 反馈 → 切换或回滚。这是把"prompt 是代码"工程化的关键路径。
机制要点:
- Prompt 与代码解耦:应用代码里只写
langfuse.get_prompt("my-prompt", label="production"),不写具体 prompt 字符串。 - Label 是部署单位:
production/staging/experiment-a等 label 指向某个具体版本号;切版本就是改 label 指向。 - Trace 自动带版本号:每次 Generation 自动记录"用了哪个 prompt 的哪个版本"。这让"v2 → v3 改完之后 p99 时间为什么涨了"这类问题有了直接的查询路径。
- 本地 cache + fallback:SDK 缓存 prompt,网络故障时能 fallback 到旧版本——这个细节决定了 prompt 系统在生产里能不能用。
4.2 Evaluation
Langfuse 提供三种评估入口:
- LLM-as-Judge(内置):在 UI 里配置 judge prompt(“判断这次回答是否准确、相关、有礼貌”),定时或实时对生产 trace 打分。Score 直接挂回 trace。
- 人工标注:在 trace 详情页可以手动打分、写评语;适合做黄金集标注。
- 自定义 Score API:你的离线评估流水线、人工流程、第三方工具可以通过 API 写 Score 进来。这条路径让 Langfuse 能融入团队既有 eval 工作流而不替代它。
值得说清楚的限制:Langfuse 的 LLM-as-Judge 是直白的"再调一次 LLM 评分",没有内置的 judge 偏见纠正、口径校准、统计显著性测试等机制。这些是 L4-8 要展开的话题——Langfuse 在评估这块是够用但不够深。
4.3 Dataset 与离线回归
Dataset 是离线测试集。基本流:
- 从生产 trace 里挑出代表性输入,挑成 DatasetItem,加入 Dataset。
- 给每个 DatasetItem 标注 expected output(黄金答案)。
- 在代码里跑一次 DatasetRun:遍历 Dataset 调用你的应用,每次输出都成为一个 trace。
- 系统自动比对 expected vs actual,给出每条的 score 和整体的 aggregate。
- UI 里直接对比不同 DatasetRun(比如 prompt v2 run vs prompt v3 run)。
这套机制把"prompt 改完了要不要上线"这个问题变成了可量化的 A/B 对比。
4.4 Session
Session 是把"一次多轮对话的所有 trace"绑成同一个浏览单位。Chatbot / Agent 类产品这个功能极其有用——你不需要在十几个 trace 之间手动切换,可以在一个页面看完整对话历史。
5. 强项与弱项
强项
- 开源 + MIT 许可证(核心;部分 EE 功能商业)。
- Self-hostable,数据完全自主可控——国内合规场景的首选。
- 框架中立:LangChain、LlamaIndex、Vercel AI SDK、自研代码、OpenAI / Anthropic 直接调用,都有 SDK 或 wrapper 支持。
- Prompt 治理是一等公民——这是与纯 trace 工具的关键差异。
- OTel 兼容(v3 之后逐步加强)——能直接接收 OpenLLMetry / Traceloop SDK 发出的 OTLP 数据。
- 活跃社区 + 频繁迭代——Discord / GitHub 都响应迅速,issue 修复速度好。
- SDK 质量好:Python 和 TypeScript 都有官方 SDK,文档清晰,example 充足。
弱项
- Self-host 部署复杂度高(v3 之后五个组件起步)。中小团队需要 ClickHouse 运维知识,否则只能跑单机将就版。
- Agent trace 可视化深度不够:树状视图能看,但 ReAct 循环、reflection 回溯这些复杂结构展示得不如专门的 Agent 工具。
- Eval 工作流不够深:相比 Braintrust 的实验框架、Opik 的统计能力,Langfuse 在评估的工程化深度上是"够用"而不是"专业"。
- 企业级特性(SSO、RBAC、审计日志)部分门控在商业版——纯 OSS 想做企业级 RBAC 要自己补。
- 国内访问体验:Hosted 版本部署在 EU / US,国内访问延迟高、偶尔被阻断;这正是为什么国内用户都倾向 self-host。
6. 何时该选 Langfuse
| 场景 | Langfuse 是否合适 | 说明 |
|---|---|---|
| 数据合规要求严格(金融、政企、医疗、国内) | ✓✓ 默认起点 | self-host + 开源审计 |
| 框架混杂(LangChain + 自研 + 直调 SDK 并存) | ✓✓ | 框架中立 |
| Prompt 治理是核心痛点 | ✓✓ | 是 Langfuse 强项 |
| 想用 OTel-native 路线但还需要 LLM-specific UI | ✓ | 兼容 OTLP 接收 |
| 追求 eval 深度(统计显著性、复杂实验设计) | ✗ | 看 Braintrust / Opik |
| 追求 Agent trace 可视化深度 | ✗ | 看 Phoenix 或专用工具 |
| 小团队、不想运维任何基础设施 | △ | 用 hosted 版(国内延迟) |
| 公司已有完整 OTel + Tempo 栈 | △ | OpenLLMetry 路线可能更顺,详见 L4-3 |
7. 自我证伪
如果以下任一条件成立,本文推荐 Langfuse 的主论证就会动摇: ① 如果 LangSmith 在 2026-2027 推出真正开源的 self-host 镜像(非企业合同门槛)——那么 Langfuse 的"开源 + self-hostable"差异化几乎被对冲掉,只剩"框架中立"这一条。截至 2026-06: LangSmith Self-Hosted 仍是企业版门槛,但 LangChain Inc. 的开源策略一直摇摆,需要持续跟踪。 ② 如果 OTel GenAI Conventions 在两年内成为事实标准,且通用 OTel 后端(Tempo、ClickHouse / Apache Doris 直接查询)开始提供"原生 LLM trace UI"——那么 Langfuse 的"专用 UI + 数据模型"价值缩水,团队会倾向 OpenLLMetry + 自建后端。部分正在发生: Phoenix / Langfuse / LangSmith 都在为这件事做准备。 ③ 如果 self-hosted v3 五组件的运维成本被中小团队评估为"不如花钱用 SaaS"——那么 Langfuse 的最大用户群(国内合规团队)会出现分裂:合规更严的咬牙运维 v3,合规相对宽松的回到 SaaS Hosted。这件事正在发生。 ④ 如果某天 Langfuse 的核心团队转向闭源 / 商业化优先(如部分开源公司的历史路径)——那么 self-hostable 承诺会遭质疑。这种风险对所有 VC-backed 开源公司都存在,是中长期变量。
8. Key Takeaways
- Langfuse 的护城河 = 调用观测 + Prompt 治理 + Eval + 离线回归 四件事缝在一个数据模型上。
- 数据模型核心:Trace → Observation(Span / Generation / Event)→ Score;Session 串多轮,PromptTemplate 独立可版本化。
- v3 self-hosted 架构 ≥ 5 组件(Web + Worker + Postgres + Redis + ClickHouse + S3-compatible),比"docker compose up"重得多,对运维能力有真实门槛。
- 同类列存 = ClickHouse 或 Apache Doris——Langfuse 官方目前只支持 CH,社区有 Doris 自行替换实验。
- Prompt 闭环是关键差异:UI 编辑 → label 部署 → trace 自动带 version → eval 反馈 → 切版本 / 回滚。
- LangChain 重度用户更适合 LangSmith;其余几乎所有场景,Langfuse 都是更现实的起点。
- 截至 2026-06 的开放问题:v3 运维门槛、与 OTel 标准的最终收敛策略、企业级 RBAC 边界。
9. 与 LangSmith 的核心差异(预告 L4-2)
不展开比较,但留四个最关键的对照点,便于你读 L4-2 时对位:
| 维度 | Langfuse | LangSmith |
|---|---|---|
| 许可 | 开源 MIT(核心) | 闭源商业 |
| Self-host | 开源 self-host 镜像,零门槛 | 企业版门槛(合同 + 较高费用) |
| 框架耦合 | 中立 | 与 LangChain / LangGraph 深度耦合 |
| 自动埋点 | 需 SDK 调用(也支持 OTel) | LangChain 应用零配置自动 |
简单结论:LangChain 重度用户 + 不在意合规 / 成本 → LangSmith 更省时;其余几乎所有场景 → Langfuse。
10. 通向下篇
L4-2 拆 LangSmith:它的数据模型与 Langfuse 有什么本质差异?LangChain 嫡系身份带来的优势具体在哪里、绑定代价具体是什么?什么场景是它的领地、什么场景它确实输给开源对手?
之后 L4-3 进入 OTel-native 路线,会和 Langfuse 形成另一组重要对照——一个是"专用平台 + 兼容 OTel",一个是"OTel-first + 通用后端"。
参考
- Langfuse Documentation. langfuse.com/docs——本文功能 / 架构 / API 描述的主要来源。
- Langfuse GitHub. github.com/langfuse/langfuse——v2 → v3 架构迁移可在 commit history 与 release notes 追溯。
- Langfuse OpenTelemetry. langfuse.com/docs/opentelemetry——OTel 兼容接收端文档。
- OpenAI Python SDK Integration. langfuse.com/docs/integrations/openai——本文 Python 代码示例的官方版本。
- ClickHouse Documentation. clickhouse.com/docs——Langfuse v3 列存依赖。
- Apache Doris Documentation. doris.apache.org——同类列存替代候选,社区有自行替换实验。